Reconciliando con autores, obras y temas de la Biblioteca Nacional
El portal de datos abiertos de la Biblioteca Nacional contiene una gran cantidad de información sobre autores, obras y temas, todos los cuales están disponibles para ser consultados a través de un portal Web muy sencillo (como se puede ver en la figura, donde estamos buscando información de Cervantes), así como utilizando tecnologías de Linked Data.

En todo momento se puede decidir si se busca y navega por autores, obras o temas, que son los tres tipos de recursos principales que se consideran en este repositorio de datos.
Accediendo a la información de un autor
Si seleccionamos la primera opción para Cervantes (que claramente representa al Miguel de Cervantes en el que todos estamos pensando), obtendremos la página de descripción de este prolífico autor de la literatura española.

Para nuestros propósitos hay algo importante en lo que nos podemos fijar, que es la URL que aparece en nuestro navegador (http://datos.bne.es/autor/XX1718747.html), que se corresponde con la página de descripción de Cervantes.
De aquí se puede obtener el identificador (URI) que se usa dentro de la BNE para referirse a este autor (http://datos.bne.es/autor/XX1718747). Por ejemplo, ¿qué ocurre si añadimos .ttl a esta dirección? Obtendremos los datos que se ven en esta página en formato RDF Turtle (http://datos.bne.es/autor/XX1718747.ttl)
Realizando búsquedas de autores
Asimismo, también podemos invocar un servicio para realizar búsquedas de autores. Esto se consigue con consultas como la siguiente:
En esta consulta estamos buscando elementos de tipo Autor que contengan la palabra CERVANTES y obtenemos los resultados en formato JSON.
A continuación tenemos un ejemplo del resultado que se obtiene:

Para Cervantes podemos ver que tenemos 418 hits, ordenados según su ranking de puntuación (que indica cómo de importante es el recurso encontrado). El primer resultado (hit) se refiere a Miguel de Cervantes Saavedra, y de este recurso obtenemos información como su URI, nombre, una descripción, fechas de nacimiento y muerte, etc. Este es uno de los servicios que utilizaremos a continuación.
Buscando obras y temas
De la misma manera en que buscamos autores, podemos buscar obras y temas. Por ejemplo, para obtener las obras en las que aparece la palabra Cervantes (por ejemplo, porque tratan de la vida y obra de este autor), utilizaremos la siguiente llamada:
Y para obtener los temas en los que aparece la palabra Cervantes utilizaremos una llamada parecida:
Ya estamos en disposición de comenzar con las reconciliaciones.
Comenzando a reconciliar con Open Refine
Teniendo en cuenta que los servicios de búsqueda anteriormente mencionados no ofrecen sus datos en JSON de acuerdo con el esquema necesario para que se pueda activar el servicio de reconciliación usado por Open Refine, lo que debemos es utilizar la funcionalidad "Add Column by fetching URLs..." que se nos ofrece para cualquier columna. Vamos a utilizar la columna title_ext para nuestro propósito.

Vamos a comenzar primero obteniendo las obras. Para ello, vamos a crear una columna Autores_BNE usando la siguiente expresión:

El "throttle delay" es una buena práctica cuando estamos haciendo este tipo de consultas masivas (se van a lanzar 3478 consultas) para no realizar un ataque de denegación de servicio a este servicio. De esta manera las consultas se van espaciando en el tiempo. Aunque tardemos un poco más, es una buena práctica cuando accedemos a este tipo de servicios y APIs (y en el caso de APIs habitualmente tenemos limitaciones de número de llamadas que podemos realizar).
Una vez realizado este proceso, hacemos lo mismo con obras y temas, creando las columnas Obras_BNE y Temas_BNE. Nos quedará algo como lo que aparece a continuación:

Filtrando los resultados obtenidos
Después de este proceso ya tenemos unas grandes cantidades de datos en JSON en las columnas Autores_BNE, Obras_BNE y Temas_BNE. Ahora es el momento de filtrar esta información para poder seguir trabajando con ellos. En concreto, lo que nos interesa en primera instancia para luego poder validar adecuadamente los resultados obtenidos es la URI del autor, obra o tema (para poder así visitar la página de la BNE en cualquier momento y comprobar si la relación es correcta), el score que esa entidad tiene (que representa su importancia) y su nombre.Para ello, debemos crear nuevas columnas basadas en los datos que tenemos. Esto se hace utilizando la funcionalidad "Add Column based on this column...", escribiendo como expresión a utilizar una expresión como la siguiente:
forEach(value.parseJson().hits.hits,h,h._score.toNumber().round()+" "+h._source.id+" "+h._source.label).join(";;;;")
De esta manera crearemos columnas cuyos valores sean del estilo:
93 XX160612 Fosfatos de Bu-Craa (El Aaiún);;;;52 XX131502 Instituto Mixto de Bachillerato "General Alonso" (El Aaiún)
Diviendo las columnas con múltiples valores
Para poder seguir con los siguientes pasos de limpieza de los datos, podemos dividir las columnas con múltiples valores que hemos generado anteriormente, convirtiéndolas en múltiples filas. Para ello utilizamos la opción de "Split multi-valued cells...", y estableciendo como separador la siguiente secuencia de caracteres ;;;;Como se puede observar, el número de filas ha crecido muchísimo (se ha multiplicado por 10).

Ahora vamos a realizar una "transposición" de las columnas en filas, con el objetivo de que podamos tratar cada uno de estos valores de uno en uno. Esto se hace utilizando la opción "Transpose cells across columns into rows", seleccionando las tres últimas columnas y denominando a las dos nuevas columnas tipo y valor. El resultado será algo parecido a lo que aparece a continuación:
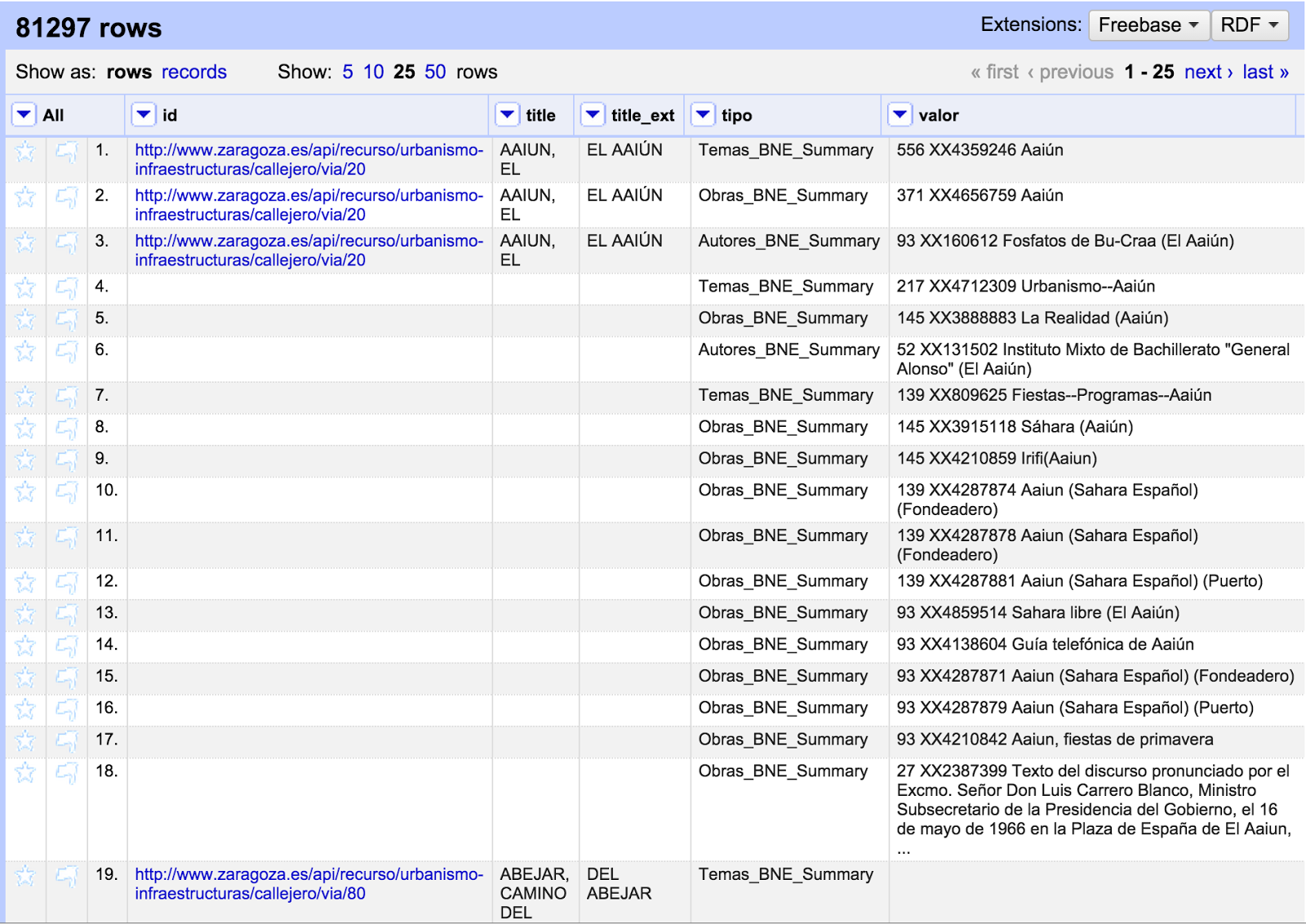
A continuación conviene rellenar los espacios en blanco que se han generado en las columnas id, title y title_ext para poder trabajar adecuadamente. Esto se hace con la función "Fill Down", y obtendremos una vista similar a la siguiente:

Generando tantas columnas como atributos queremos tratar
Finalmente, dividimos cada columna en varias, para atender a los distintos atributos que hemos ido generando en cada caso. Para ello utilizamos la opción de "Split into several columns...", y renombramos las columnas con los nombres score, idBNE y labelBNE.Y generamos la URI de BNE creando una nueva columna URI_BNE con la siguiente expresión:
"http://datos.bne.es/"+cells["tipo"].value.toLowercase()+"/"+cells["idBNE"].value
Con todo este procesado, ya tenemos un fichero de 81297 filas donde se relacionan calles con autores, obras y temas. Ahora habrá que validarlo de manera que podamos determinar todos los valores que son adecuados para entender a qué autores están dedicadas nuestras calles, así como con qué obras y temas están relacionadas.
El script completo en Open Refine se encuentra disponible en https://gist.github.com/ocorcho/ce3954b766a0c1651c7b
No hay comentarios:
Publicar un comentario